Haciendo Ciencia Abierta
Clase 6
2024-07-08
Ejemplo: Encuesta

¿Qué es preservación de los datos?


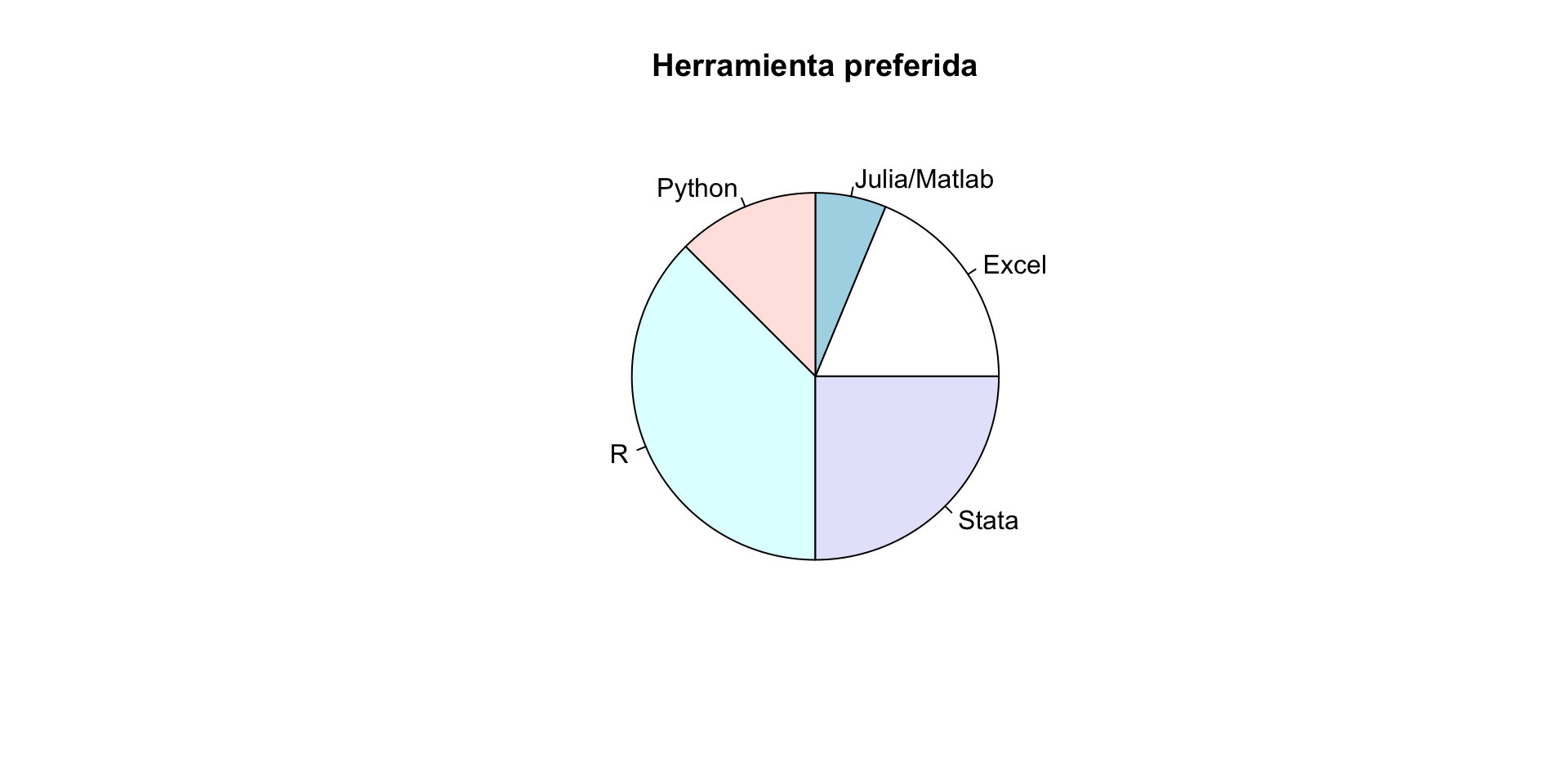
Resultados: Herramientas
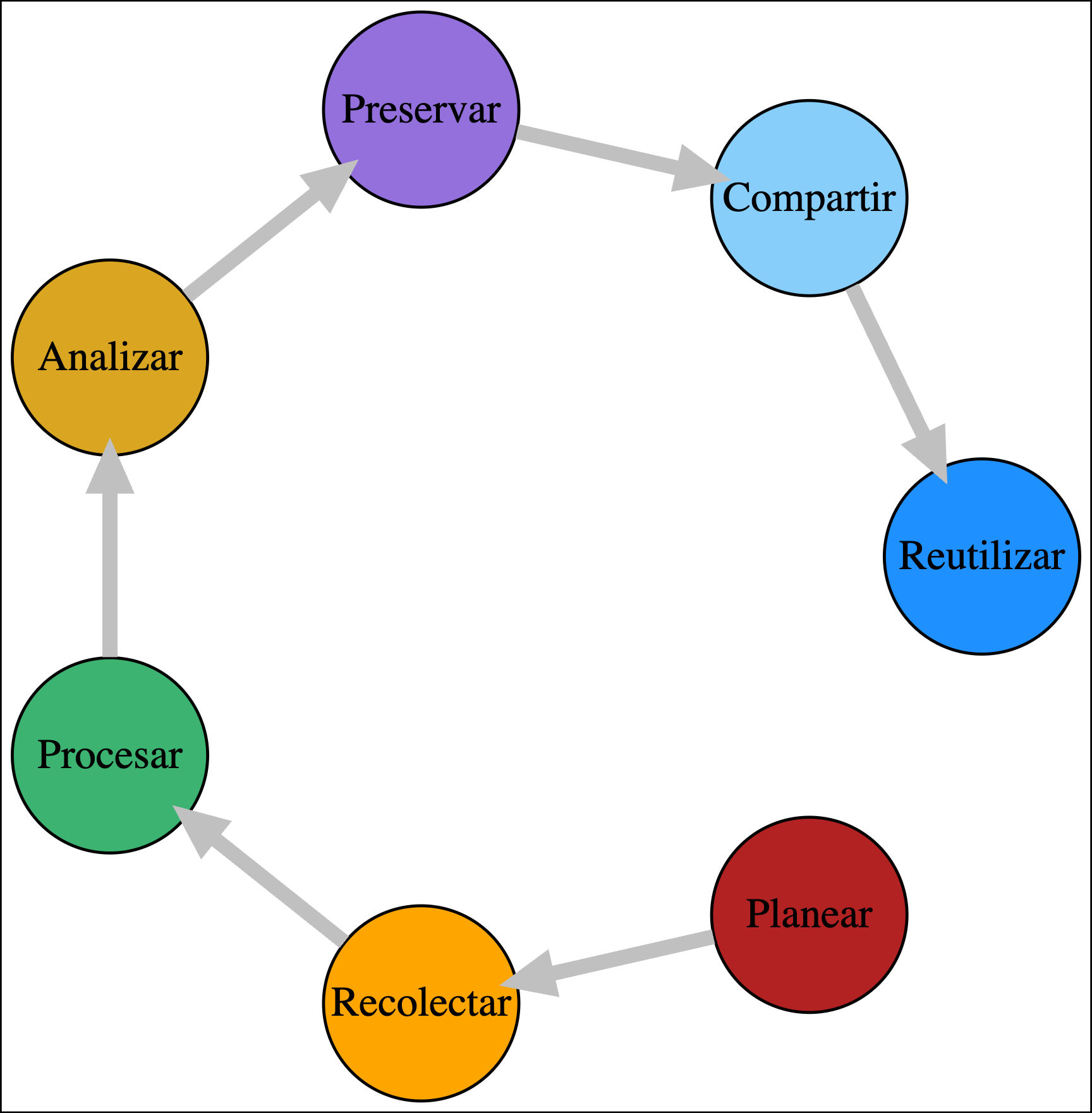
Ciclo de vida de los datos
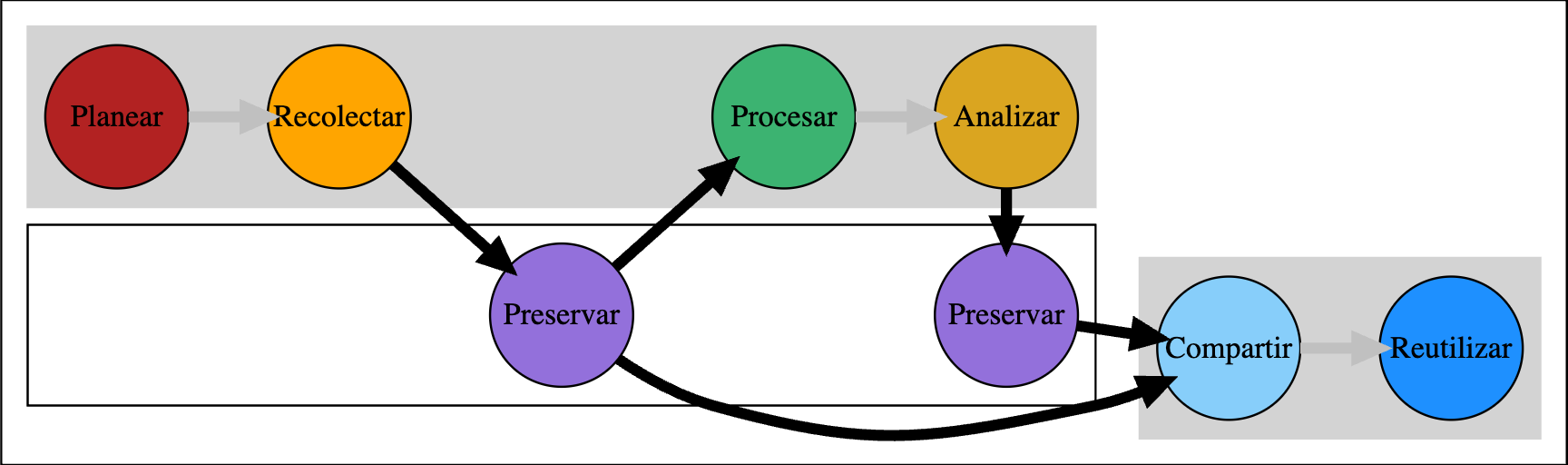
- Preservar en el camino, permite mayor transparencia
¿Preservar datos?
- Archivar en un lugar confiable
- Tener un identificador persistente (principio F1)
- Metadatos accesibles (principio A2)
- Metadatos y datos indexables (principio F4)

Bonus: Documentación para Machine Learning

Ejemplo de guía
Información relevante:
- Recolección terminó el 19 de junio a las 17:05
- Se modificó el 21 de junio
- Se analizó el 21 de junio
- Se modificó el formato de la variable fecha el 27 de junio a las 08:06
Sugerencia de flujo de trabajo para tareas:
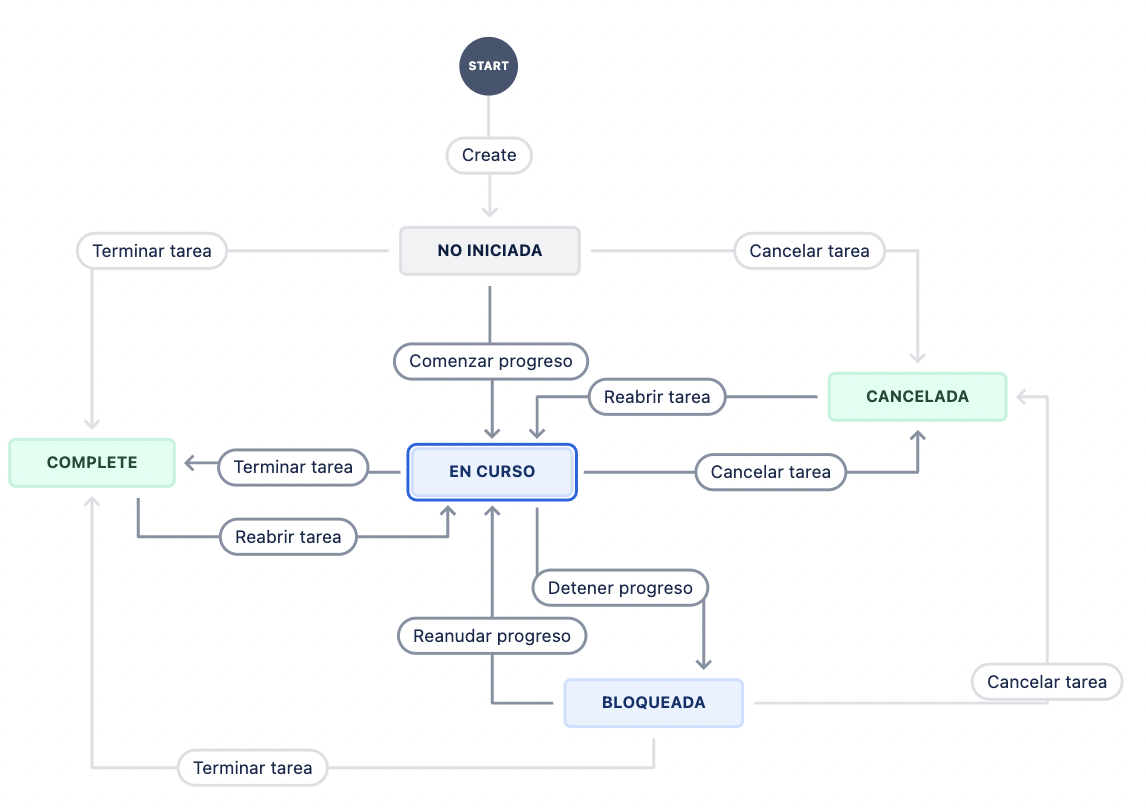
Demo con GitHub
Veamos como usar los Issues y GitHub Projects

Rompecabezas de la investigación cuantitativa
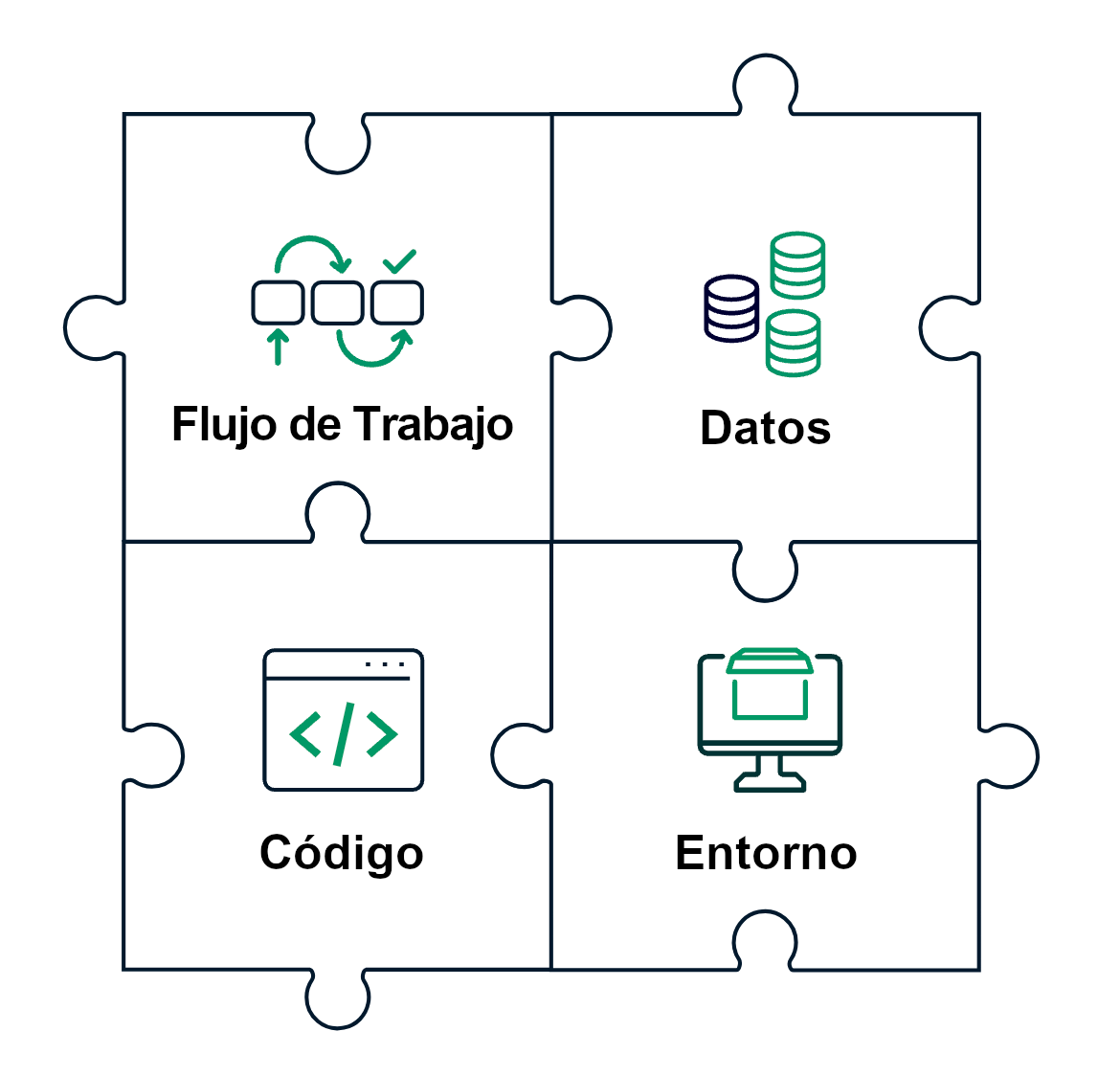
Rompecabezas de la investigación cuantitativa
- Flujo de Trabajo ✅
- Datos ✅
- Código ✅
- Entorno 🏁
- Contenedores
- Máquina Virtual
- Sistema Operativo (NixOS)

Nuestra caja de herramientas
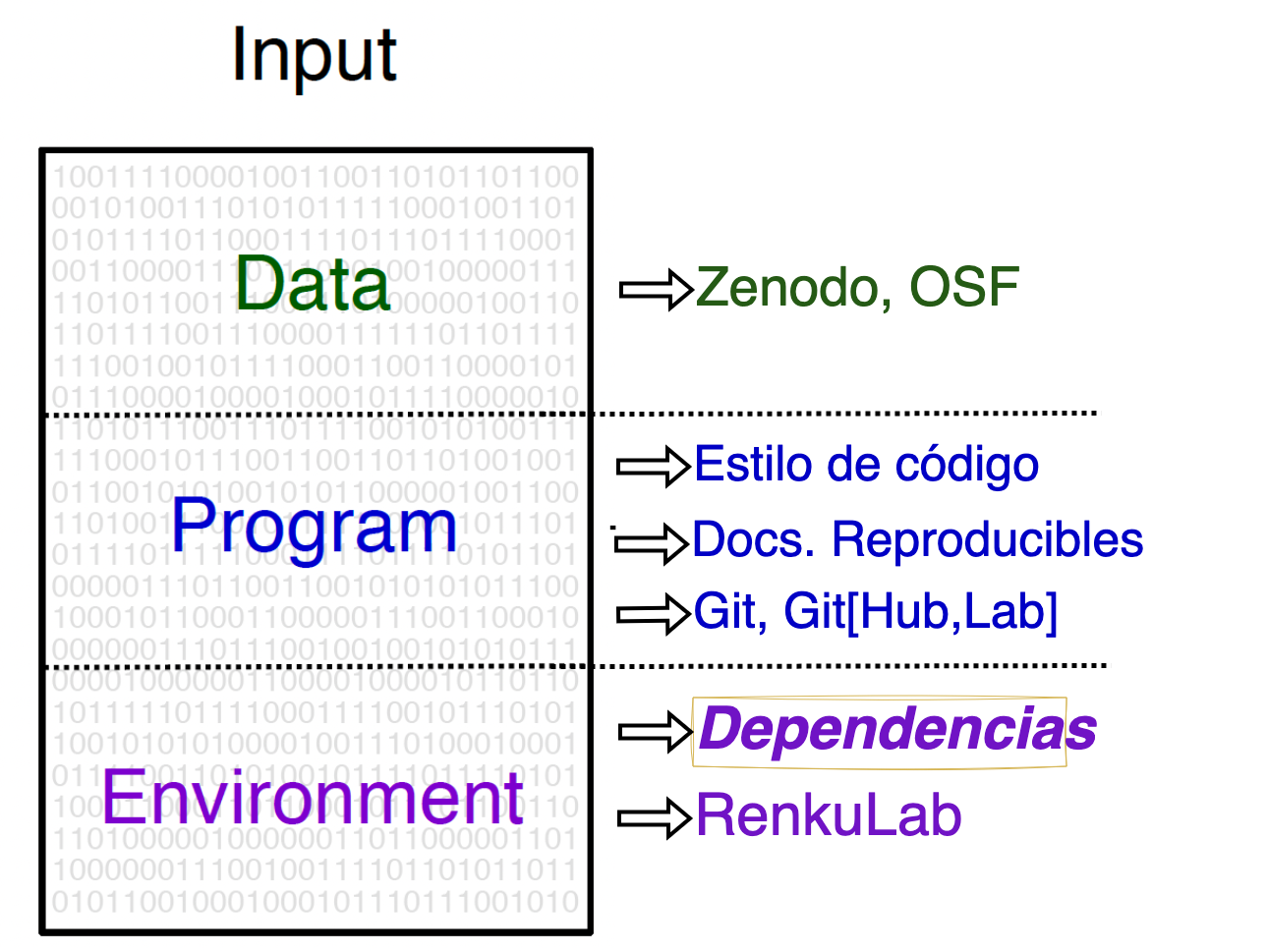
Proyecto Transversal: Flujo de Trabajo
Documento Reproducible en R Markdown y en Jupyter 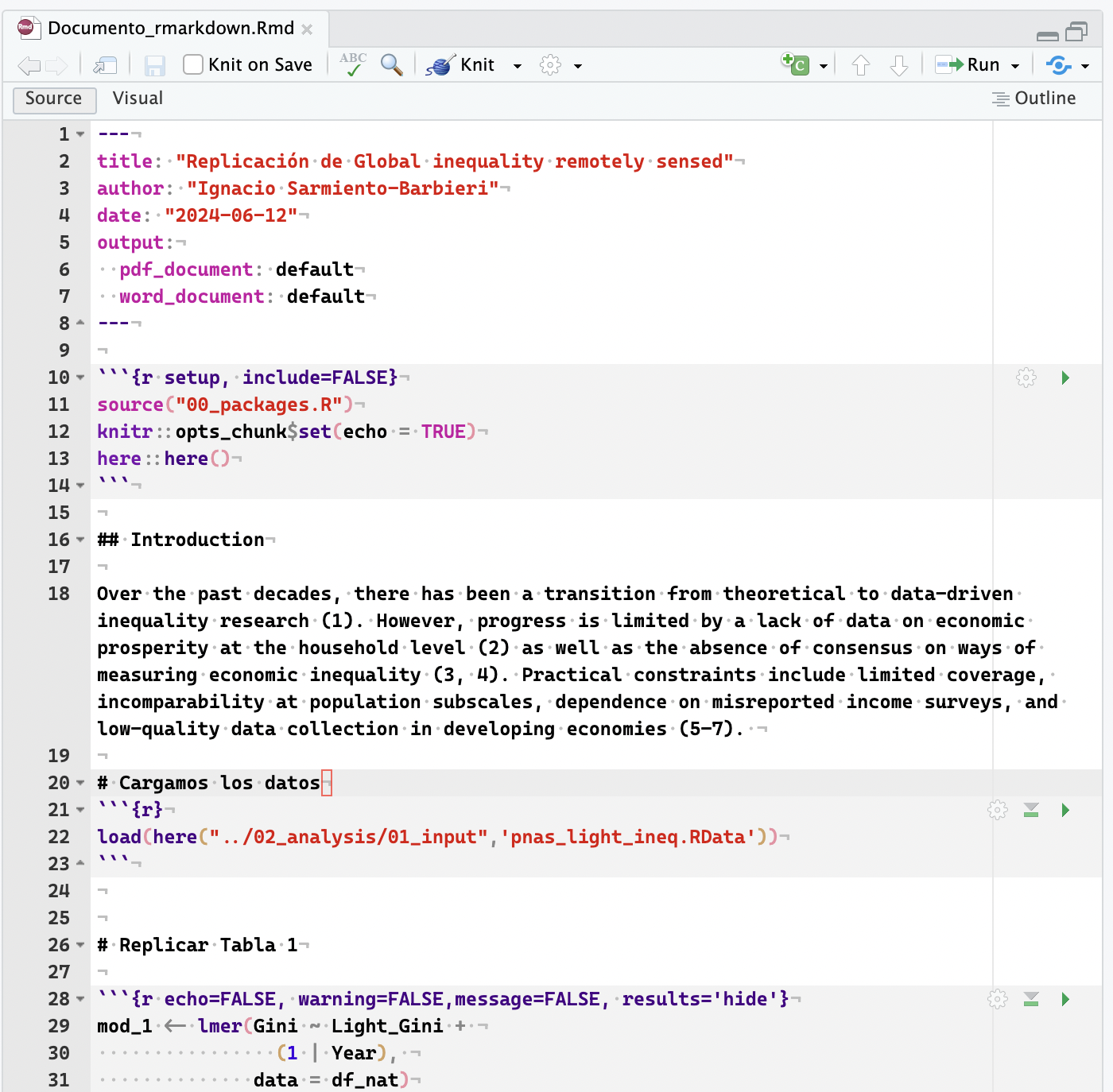
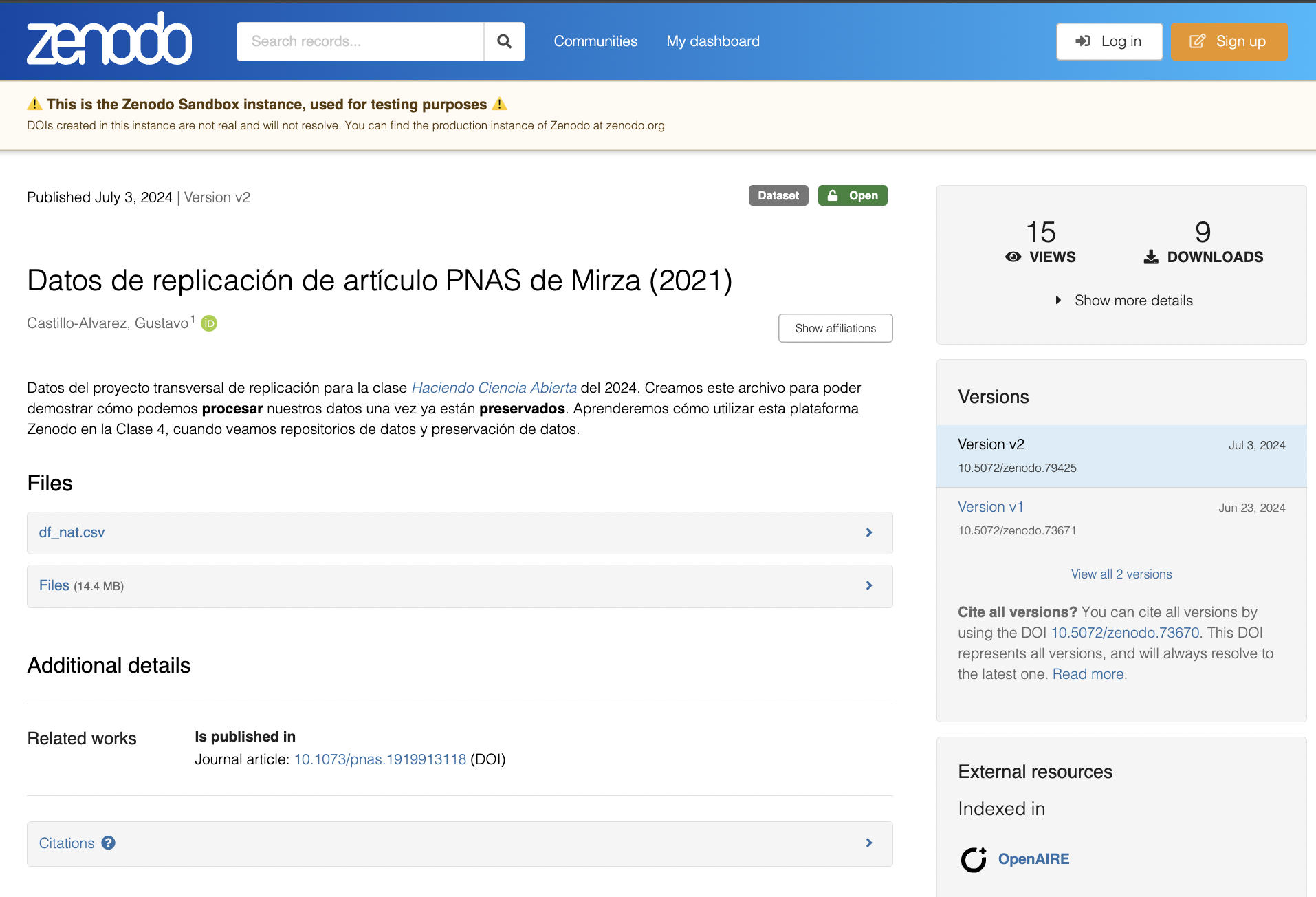
Proyecto Transversal: Datos
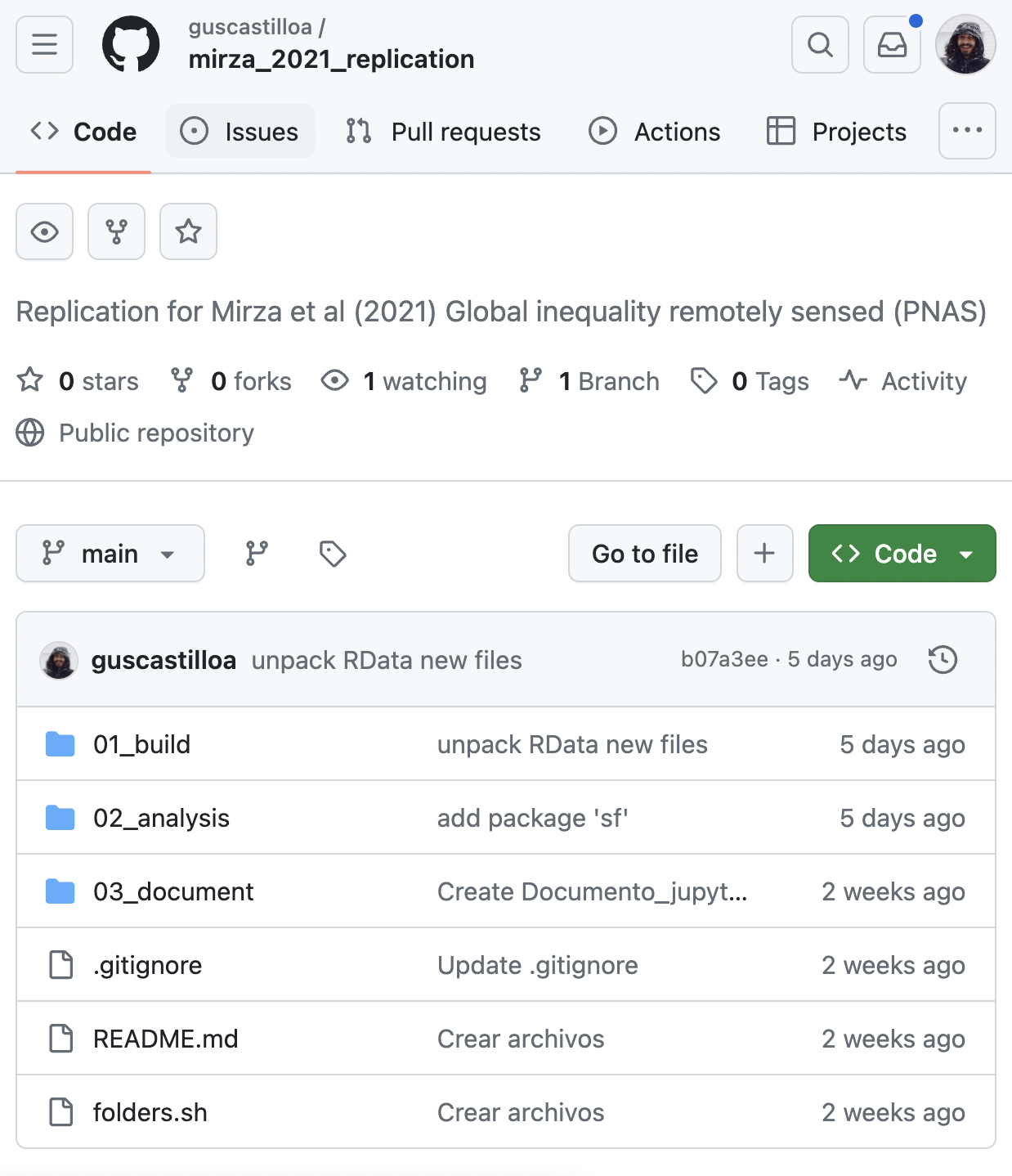
Proyecto Transversal: Código
Proyecto Transversal: Entorno
- Proyecto en RenkuLab
- Especificar dependencias e información de sistema
Manos a la obra

![]()